近日,医学院硕士研究生万梦璇、博士后赵彦彭在《Nature Communications》发表了名为“A meta learning and task adaptive approach for drug target affinity prediction”的研究论文。针对现有药靶亲和力(DTA)预测模型在少样本、未见过靶标场景下的性能短板,研究团队提出了一种基于元学习框架的新型预测模型AdaMBind,该模型集成了元学习模块、自适应任务模块和标签噪声注入策略,通过动态“由易到难”的任务调度机制,提升模型的训练效率和稳健性,实现对未见过靶标的精准亲和力预测,为少样本场景下的药物发现提供强有力的计算工具。

尽管深度学习在DTA预测中已取得诸多突破,但实际应用中仍面临两大关键瓶颈:一是多数模型在样本有限的情况下难以有效学习靶标表征,而现实中大量靶标缺乏充分表征,导致药物-靶标相互作用数据极度稀疏,严重限制模型的特征提取能力;二是主流方法缺乏靶标特异性适应和元知识迁移机制,难以应对未见过靶标的预测任务,无法快速利用少量实验数据形成对新靶标的特异性理解并实现可靠预测。元学习作为“学会学习”的有效框架,虽已被应用于DTA预测,但现有元学习方法存在任务采样不合理、易受噪声任务干扰、依赖训练任务与测试任务相似性等缺陷,仍需进一步优化以提升模型在少样本、跨靶标场景下的泛化能力。
为了缓解现有DTA预测模型在少样本、未见过靶标场景下的应用瓶颈,研究团队创新研发了一种基于元学习框架的DTA预测模型(AdaMBind)。该模型集成三大核心组成部分:元学习模块、自适应任务模块及标签噪声注入策略。其中,元学习模块为模型提供“学会学习”的核心能力,助力模型快速利用少量数据实现知识迁移;自适应任务模块通过“由易到难”的动态调度机制,实现对高价值任务的优先学习;标签噪声注入策略则进一步提升模型的稳健性。三者协同作用,构建起高效、稳健的DTA预测架构,可实现对未见过靶标的精准亲和力预测。
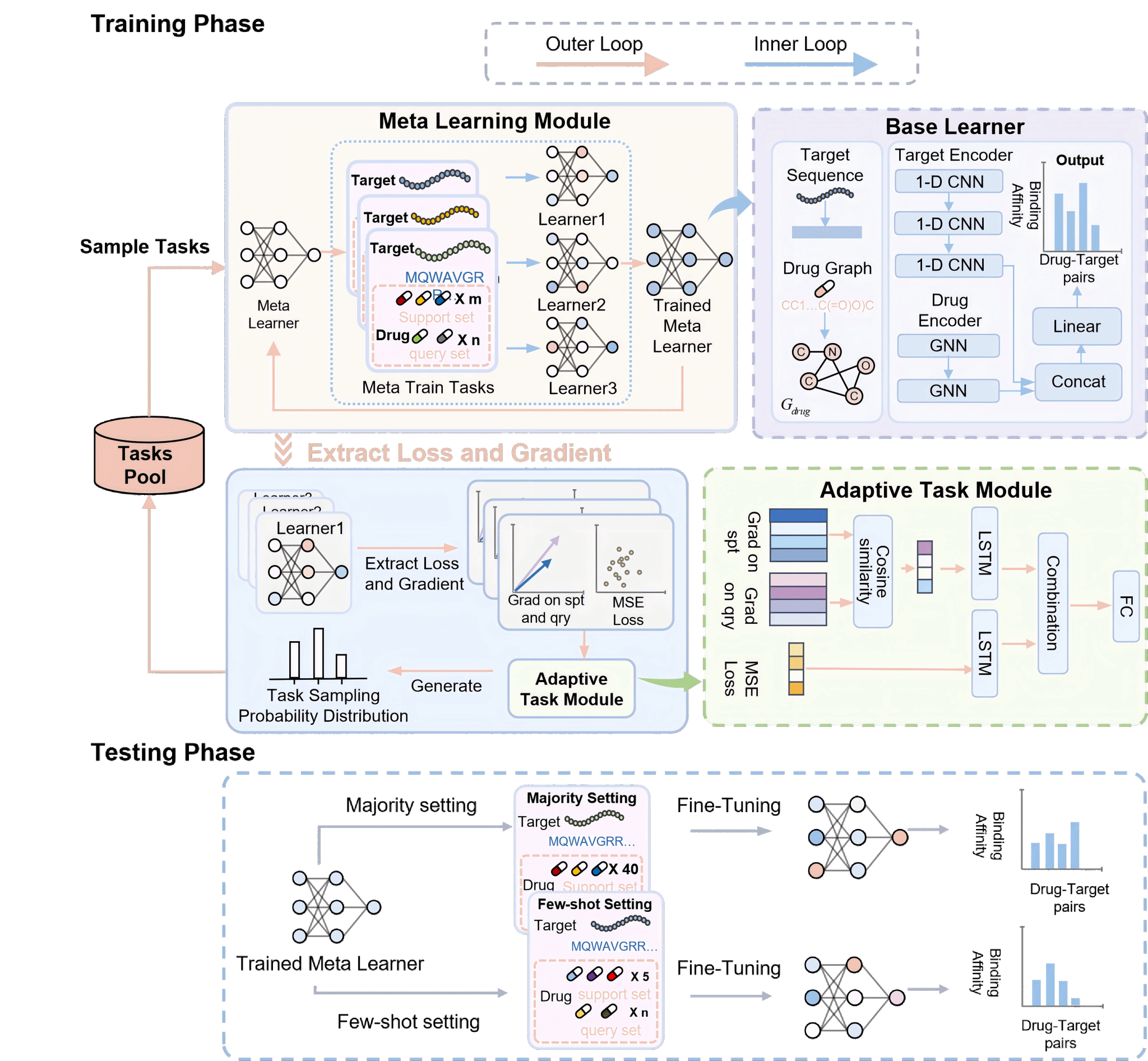
图.基于元学习和任务自适应机制的的药靶亲和力预测的方法框架图
AdaMBind通过对三个基准数据集(BindingDB、KIBA、Davis)的测试,并与8种基线模型进行比较,展示了其优越的性能,无论是在多样本还是小样本设置下,均显著优于各类基线模型。此外,自适应任务机制的有效性得到验证,其“由易到难”的动态任务调度策略,有效提升了模型的训练效率和泛化能力,与理论预期高度一致。
为了验证AdaMBind的实际应用价值,研究团队开展了虚拟筛选实验及FLT3潜在抑制剂预测实验。实验结果表明,AdaMBind能够有效筛选出具有潜在活性的化合物,成功预测出FLT3潜在抑制剂,充分证明其可加速从理论模型到实际药物开发的转化过程,为药物研发提供有力支撑。
综上,本研究提出的AdaMBind模型通过元学习与自适应任务模块的协同作用,有效解决了少样本、未见过靶标场景下DTA预测的核心难题。AdaMBind不仅为少样本DTA预测提供了稳健的框架,还在虚拟筛选和FLT3抑制剂发现中展现出良好的实际应用价值,有望加速早期药物研发进程,为新兴、研究不足靶标的药物开发提供高效、可靠的计算工具。
上海大学医学院为该论文的第一单位,医学院硕士研究生万梦璇、博士后赵彦彭为该论文的第一作者,军事医学研究院的伯晓晨、何松研究员以及上海大学昝鹏教授为该论文的共同通讯作者。研究得到国家自然科学基金委、国家重点研发计划、上海市科委的大力资助和支持。
原文链接:https://www.nature.com/articles/s41467-026-70554-5




